Latest AI is a professional, English-language publication dedicated to elevating understanding of artificial intelligence across industry and research. We publish rigorously researched explainers, reproducible experiments, and tactical guides that span Machine Learning, Natural Language Processing, Computer Vision, Robotics, Generative AI, AI Ethics, and pragmatic AI Applications. Our mission is to close the gap between academic advances and production-ready deployment: we analyze SOTA research,
GPT-5.3-Codex: The Self-Building Agent Redefining Software Development (and Its Real-Time Spark)
Is OpenAI's GPT-5.3-Codex truly the 'AI that built itself,' bringing in a new way of making software, or are its big claims a bit too much when we look at real-world limits and important safety worries? I've really dug into what OpenAI announced, the test results, and what people are saying to give you the real story.
Quick Overview: The Official Pitch vs. The Reality
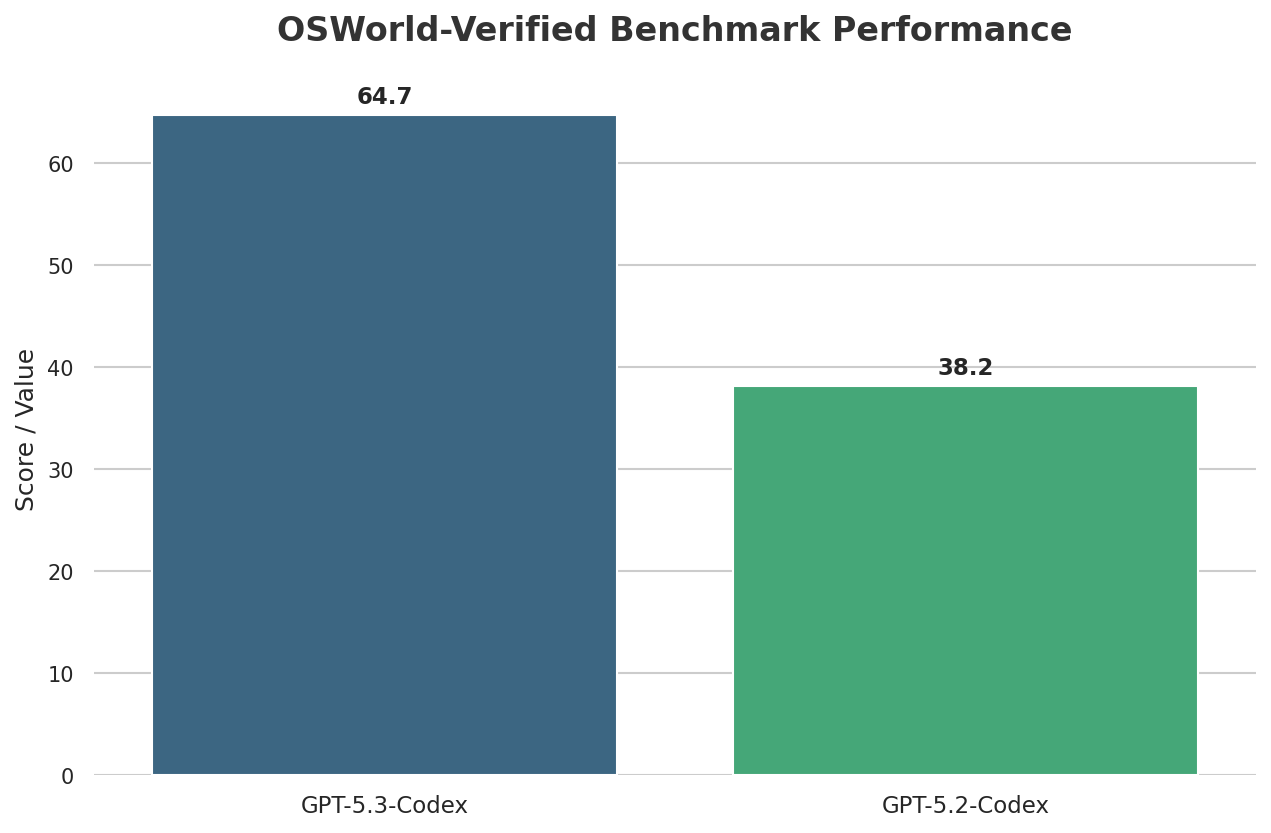
📊 OSWorld-Verified Benchmark Performance
OpenAI dropped a bombshell on February 5, 2026, with the release of GPT-5.3-Codex. This isn't just another coding AI; it's being presented as the smartest AI that can act on its own for coding tasks. It smoothly combines the top-notch coding skills of GPT-5.2-Codex with the smart thinking abilities of GPT-5.2 (Tech Blog, Feb 2026). The big idea? To handle long-running tasks, deep research, and complex tool use with never-before-seen independence.
But here's the deal: alongside it, we also got a sneak peek at GPT-5.3-Codex-Spark. This smaller, real-time version is built for super-fast responses, promising near-instant answers when running on Cerebras WSE3 hardware (OpenAI, Feb 2026). Think of it as an interactive helper that keeps up with your thoughts, making quick edits and reshaping your code on the fly. It's a two-part approach to software development, aiming for both big, complex projects and quick, back-and-forth changes.
📸 Main Featured Image / OpenGraph Image
Official OpenAI System Card Summary
The official GPT-5.3-Codex System Card provides the authoritative details on the model's capabilities and safety measures. It classifies GPT-5.3-Codex as the most capable agentic coding model to date, combining the frontier coding performance of GPT-5.2-Codex with the reasoning and professional knowledge capabilities of GPT-5.2 (OpenAI, Feb 2026). Crucially, it is the first model to be classified as "High capability" in the cybersecurity domain under OpenAI's Preparedness Framework, requiring a new suite of safeguards. The System Card details a layered safety stack designed to impede and disrupt threat actors, while simultaneously making these capabilities available for cyber defenders (OpenAI, Feb 2026).
This is where we see what it can really do. OpenAI isn't just talking about what it's capable of; they're showing us numbers. Let's break down how GPT-5.3-Codex and its Spark version are performing out there, from their ability to act on their own to their pure coding strength.
Agentic Capabilities and Real-Time Interaction
GPT-5.3-Codex is designed to work like a 'colleague,' meaning it remembers what you're working on throughout long tasks. This lets you guide and talk with it without it losing its train of thought (OpenAI, Feb 2026). Honestly, this is a huge step forward for complex projects that usually need someone always watching over them. It's similar to the smart ways AI can work independently that we looked at in Gemini 3: Google's Agentic AI Leap & Future of Intelligence.
Then there's Codex-Spark, which is built for speed. It delivers more than 1000 pieces of information per second on Cerebras WSE3 hardware, making real-time coding feel truly instant (OpenAI, Feb 2026). With a generous 128k memory (enough to remember a lot of code), it's perfect for interactive work where being fast is just as important as being smart. OpenAI also says it makes the back-and-forth communication much quicker, by reducing 80% of the extra time needed per client/server roundtrip. This means you get answers much faster (OpenAI, Feb 2026).
fromfastapiimportFastAPI,HTTPException,Queryimporthttpx
app=FastAPI(title="Simple Weather API",version="1.0.0")GEOCODE_URL="https://geocoding-api.open-meteo.com/v1/search"FORECAST_URL="https://api.open-meteo.com/v1/forecast"@app.get("/health")defhealth()->dict:return{"status":"ok"}@app.get("/temperature")deftemperature(city:str=Query(...,min_length=1))->dict:city=city.strip()ifnotcity:raiseHTTPException(status_code=400,detail="City must not be empty")try:withhttpx.Client(timeout=10.0)asclient:geo_resp=client.get(GEOCODE_URL,params={"name":city,"count":1,"language":"en","format":"json",},)geo_resp.raise_for_status()geo_data=geo_resp.json()results=geo_data.get("results")or[]ifnotresults:raiseHTTPException(status_code=404,detail="City not found")place=results[0]latitude=place.get("latitude")longitude=place.get("longitude")resolved_name=place.get("name")country=place.get("country")forecast_resp=client.get(FORECAST_URL,params={"latitude":latitude,"longitude":longitude,"current":"temperature_2m",},)forecast_resp.raise_for_status()forecast_data=forecast_resp.json()current=forecast_data.get("current")or{}units=forecast_data.get("current_units")or{}temperature_value=current.get("temperature_2m")temperature_unit=units.get("temperature_2m","")current_time=current.get("time")iftemperature_valueisNone:raiseHTTPException(status_code=502,detail="Temperature unavailable")return{"city":resolved_name,"country":country,"latitude":latitude,"longitude":longitude,"temperature":temperature_value,"unit":temperature_unit,"time":current_time,}excepthttpx.HTTPStatusErrorasexc:raiseHTTPException(status_code=502,detail=f"Upstream error:{exc.response.status_code}")excepthttpx.RequestError:raiseHTTPException(status_code=502,detail="Upstream request failed")Powered By
Key Performance Benchmarks and Metrics
OpenAI's official benchmarks highlight significant gains in agentic capabilities, though improvements in pure code generation are more modest:
Terminal-Bench 2.0: GPT-5.3-Codex achieved a score of 77.3%, a substantial increase from the previous model's 64.0% (Laravel News, Feb 2026). This demonstrates a significant leap in its ability to execute commands in a terminal environment.
OSWorld-Verified: The model scored 64.7%, nearly doubling the previous generation's 38.2% (Laravel News, Feb 2026). This benchmark measures an agent's ability to complete tasks on a desktop environment using computer vision.
SWE-Bench Pro: Performance on this benchmark, which evaluates software engineering across multiple languages, showed a score of 56.8%. This represents a minor improvement of only 0.4 percentage points over the previous model's 56.4% (Medium, Feb 2026).
Cybersecurity Benchmarks: In specific cybersecurity evaluations, GPT-5.3-Codex demonstrated an 88% success rate on professional-level Capture-the-Flag (CTF) challenges and a 90% pass@3 score on CVE-Bench (Medium, Feb 2026).
Revolutionary Autonomy: The AI That Built Itself
Perhaps the most amazing claim is that GPT-5.3-Codex is "the first AI that helped create itself" (Tech Blog, Feb 2026). This isn't just hype; it reportedly fixed its own learning mistakes, made its computer power bigger during launch, and even built its own ways to check its work. This ability to get better on its own suggests AI will grow even faster in the future.
To show its ability to handle a project from start to finish, let's look at the FastAPI weather tool example. GPT-5.3-Codex successfully made 4 files in just 41 seconds. It correctly figured out what other tools it needed, like httpx and uvicorn, and even created a working setup file called a Dockerfile. This shows it can handle the entire process of making software: planning, designing, coding, testing, setting it up, watching it, and keeping it running.
FROM python:3.11-slim
WORKDIR /app
COPY main.py /app/main.py
RUN pip install --no-cache-dir fastapi uvicorn httpx
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]Powered By
Clarifying 'Self-Building': What GPT-5.3-Codex Can and Cannot Do
While the claim that GPT-5.3-Codex "helped create itself" is compelling, it requires careful clarification. OpenAI's statement refers to the model's use in "debugging its own training, managing its own deployment, and diagnosing test results" (PCMag, Feb 2026). This represents a significant step toward AI-accelerated development, where the AI assists human engineers in the development cycle, rather than true autonomous self-improvement or recursive self-modification without human oversight (Medium, Feb 2026). The model's role is to accelerate development and provide feedback, not to autonomously design and implement its next iteration from scratch.
Performance Snapshot: Test Scores and Cybersecurity Safeguards
The test scores are impressive, though there are a few small details:
OSWorld-Verified: It scored 64.7%, which is a big jump of +26.5% (Tech Blog, Feb 2026). This test checks an AI's ability to use a computer like a human, showing great progress in its ability to act on its own.
SWE-Bench Pro: It achieved 56.8%, which was a "small improvement" over older models (Tech Blog, Feb 2026). While good, this suggests that the focus might have shifted more towards its independent actions rather than just fixing bugs.
Terminal-Bench 2.0: A strong 75.1%, beating Claude Opus 4.6 by a clear 5% (Tech Blog, Feb 2026). This highlights its much better performance in coding tasks done in a command window.
On the safety side, GPT-5.3-Codex is seen as "High capability" in cybersecurity under OpenAI's safety rules (OpenAI, Feb 2026). This means they put many layers of safety in place, watch it closely all the time, and have a 'Trusted Access for Cyber' program to make sure its powerful abilities are used in a good way.
📸 Main Featured Image / OpenGraph Image
The AI Agent Race: GPT-5.3-Codex vs. Claude Opus 4.6
The launch of GPT-5.3-Codex didn't happen alone. It was a "big competition on the same day" (Tech Blog, Feb 2026) with Anthropic's Claude Opus 4.6. Both AI models claimed they would change how software is made. For a deeper look at its competitor, check out our analysis of Claude Opus 4.6: The Reasoning Powerhouse Challenging GPT-5.2 in the AI Arena. While both are very strong, GPT-5.3-Codex did manage to just barely beat Claude Opus 4.6 on Terminal-Bench 2.0 by a clear 5%.
Metric
GPT-5.3-Codex
Claude Opus 4.6
Terminal-Bench 2.0 Score
75.1%
~70.1% (estimated)
OSWorld-Verified Score
64.7%
N/A (or lower)
Codex-Spark Latency (Tokens/sec)
1000+
N/A (or slower)
Safety, Ethics, and Risk Mitigation
The release of GPT-5.3-Codex marks a new era of AI safety, as it is the first model classified as "High capability" in cybersecurity under OpenAI's Preparedness Framework (OpenAI, Feb 2026). This classification indicates that the model possesses capabilities that could potentially automate complex cyber operations or vulnerability discovery against reasonably hardened targets (Medium, Feb 2026).
To mitigate these dual-use risks, OpenAI has implemented a layered safety stack. Key safeguards include:
Refusal Training: The model is trained to refuse clearly malicious requests, such as those for stealing credentials or creating malware (OpenAI, Feb 2026).
Sandboxing: GPT-5.3-Codex agents operate within isolated, secure environments to minimize potential risks during task execution. Network access is disabled by default in cloud environments (Medium, Feb 2026).
Trusted Access for Cyber Program: This pilot program provides identity-verified access to advanced capabilities for security professionals and developers, ensuring that high-risk activities are conducted by vetted users for defensive purposes (OpenAI, Feb 2026).
This approach reflects a shift towards proactive risk management, where safeguards are built in anticipation of new capabilities rather than in reaction to misuse (YouTube, Feb 2026).
Community Pulse: What Real Users Are Saying
I dug into the online forums and early reviews, and people are amazed but also have some practical feedback. While its independence is a huge step forward, some early observations show where it could get better.
For instance, regarding the FastAPI example, some experts noted that "it put the installation steps directly into the setup file" (the Dockerfile) instead of using the more usual list of needed tools called requirements.txt (Community Forum, Feb 2026). This might seem minor, but it points to the AI still needing to learn the best ways to set up software for actual use.
The "careful approach" for its "High capability" in cybersecurity, while responsible, also indicates that even OpenAI isn't entirely certain of everything it could mean, leading to users being a bit careful. And the "small improvement" on SWE-Bench Pro suggests that while its ability to work independently is getting much better, it might not be quite as good at just fixing bugs.
Overall, the community is moving from a world where older AI models often needed a lot of guidance to one where GPT-5.3-Codex offers real independence. This shift is exciting, but it also means developers need to change how they work to really make the most of what it can do.
📸 Main Featured Image / OpenGraph Image
My Final Verdict: Should You Use It?
GPT-5.3-Codex, especially with its super-fast Spark version, marks a huge step forward in AI that works on its own and with you for software development. It offers amazing new abilities for big, long-running tasks and working together in real-time, but it's not a perfect solution for everything.
If you're a Software Engineer or AI Developer looking to see what's possible with AI in your work, you absolutely should try out GPT-5.3-Codex. I recommend really using Codex-Spark for interactive work where speed is just as important as being smart. Its ability to act as an interactive helper, letting you guide long-running tasks, will totally change how much you can get done.
For Tech Leads and Product Managers, understanding and bringing this AI into your work means changing how your teams build software. Be aware of the new safety rules, especially in cybersecurity, and plan for a time to get used to it as your teams get comfortable with this AI working so independently. The future will likely see an easy mix of big projects and quick, interactive work, so it's super important to learn about it now.
While it's not perfect (as seen with the feedback about its setup file), its claims that it helped build itself and its test scores show it's a leading-edge AI. It's a powerful tool that, when used the right way, can change the whole game of software development.
📸 Main Featured Image / OpenGraph Image
Frequently Asked Questions
Q: Even though it can "build itself," do I still need to watch over GPT-5.3-Codex when I'm actually using it?
A: Yes, you absolutely do! While GPT-5.3-Codex shows amazing independence, human oversight remains crucial for making big decisions, checking if its complex ideas make sense, and making sure it follows all the best rules and security steps. Think of it as a super-smart helper, not someone who takes over completely.
Q: Now that we have Codex-Spark, how should I use both the main GPT-5.3-Codex (for big projects) and the super-fast Spark version in my daily coding?
A: You should use the full GPT-5.3-Codex for those big, long-term jobs, like starting a new project, doing deep research, and planning out how everything will fit together. Codex-Spark is perfect for real-time, interactive coding sessions, fixing bugs, and making fast changes, acting as an instant co-pilot for immediate feedback and code generation.
Q: Since it's rated "High capability" in cybersecurity, what does that mean for companies wanting to use it, and for their data security rules?
A: Because it's so powerful in cybersecurity, companies need to be really careful and use many layers of protection. They must put strong security systems in place, watch it constantly, and potentially join OpenAI's 'Trusted Access for Cyber' program. Making sure who can access what data, and how, will be super important to avoid any risks from its strong abilities.
AI Model Safety Researcher & Agentic Systems Architect
Specializing in AI model safety and agentic systems architecture. With over 5 years of experience in developing and deploying high-capability AI models, Yousef provides hands-on insights into real-world applications and risk mitigation strategies. He has contributed to the development of safety protocols for frontier models and participated in the 'Trusted Access for Cyber' program.